
{kind=link}
Why IVON might be what you need
Are you a deep learning (DL) practitioner who has always been using SGD/Adam? If so, our new optimizer, IVON, might be a better option for your next DL projects.
(And no, I promise IVON isn’t yet another obscure optimizer that performs 1% better while being 100% slower ![]() )
)
IVON is proposed in our paper “Variational Learning is Effective for Large Deep Networks”, accepted at ICML 2024 as a spotlight paper. This work results from a long collaboration dating back to 2021, and I had the pleasure to implement and revise this optimizer many times with my own hands, and witness how a great idea can be realized and gradually improved.
The goal of this post is to offer an easy introduction to IVON for the general audience, and explain why and how it can help you train neural networks more effectively.
For researchers who wish to understand the technical details, I would recommend this excellent post written by none other than Emti himself, the “mastermind” behind this project and an expert in the field. And of course, please also feel free to read our paper.
So, what is “eye-von” exactly?
Glad you pronounce it right! ![]() IVON is an optimizer derived from a Bayesian modeling of network parameters, and it uses natural gradient mean-field variational inference.
IVON is an optimizer derived from a Bayesian modeling of network parameters, and it uses natural gradient mean-field variational inference.

Don’t worry if you don’t understand these technical terms. IVON is, just like SGD or Adam, a general-purpose neural network optimizer, and it can be used as a drop-in replacement in your deep learning projects.
What sets IVON apart is that it does not look for a specific set of parameters like SGD or Adam, but instead accounts for the uncertainty of model choice and tries to fit a Gaussian distribution over the most probable parameter configurations.
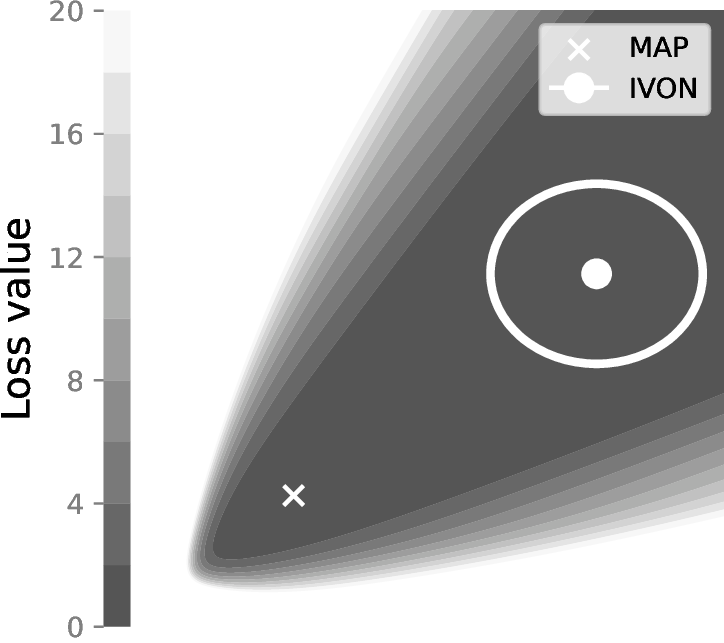
This can be interesting especially for two reasons:
- It locates flat minima in the loss landscape, which is hypothesized to generalize better (i.e. better test-time performance).
- The learned Gaussian encodes additional variance information which, as we will see shortly, opens many new possibilities.
We have provided a Google Colab notebook for the illustrated 2D example, feel free to try it out!
Why use IVON?
There are already so many advanced DL optimizers out there, why would IVON deserve a spotlight? For me, there are three main reasons which make IVON special.
IVON is fast and scalable
It is easy to outperform the rather basic SGD and Adam optimizers, but harder to do so without significant performance overhead.
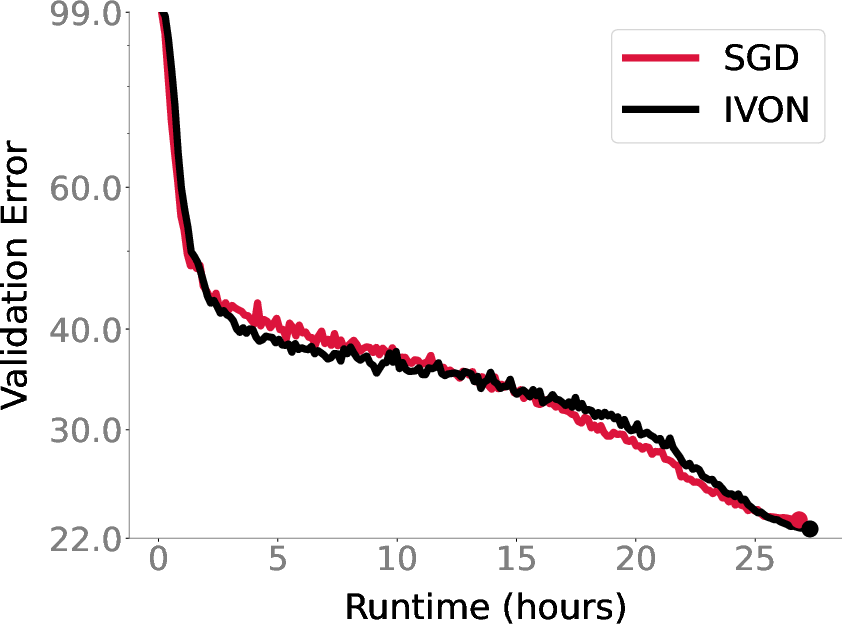
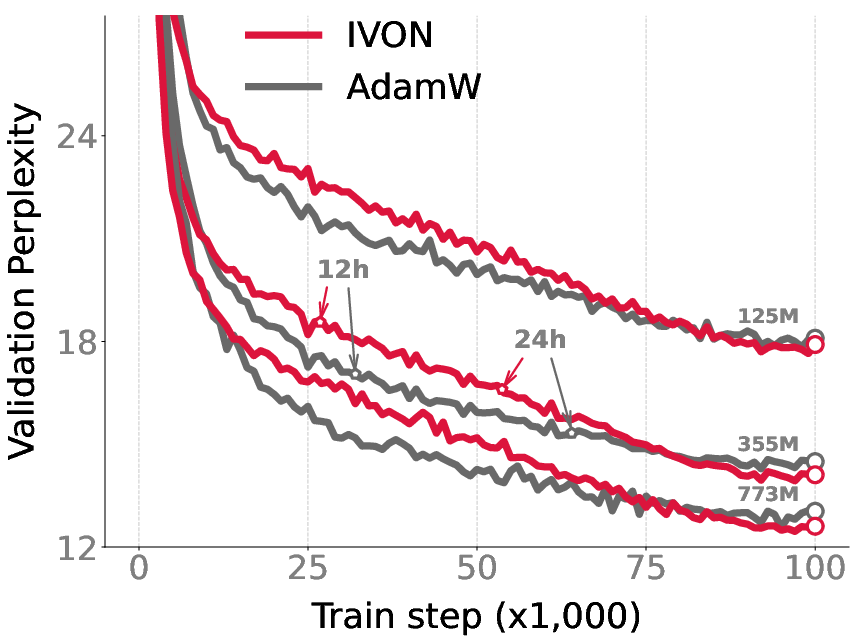
Luckily, IVON is both fast and scalable. Our experiments show that (see figure below), for image classification tasks on CIFAR-10/ImageNet, IVON exhibits nearly no overhead; For GPT-2 training, IVON has less than 20% runtime overhead compared to Adam.1
Oh, did I mention that IVON is the first variational learning method to successfully train GPT-2? We are able to scale IVON to train a GPT-2 model with 773 million parameters on OpenWebText from scratch, and we achieve better results compared to AdamW2.
IVON improves test results and uncertainty estimation
Yes, rest assured that IVON can consistently outperform SGD and Adam in our experiments, for both CV and NLP tasks.
Being a Bayesian deep learning (BDL) method, IVON also enables high-quality uncertainty estimation. In fact, an earlier version of IVON won first place in the NeurIPS BDL competition in 2021.
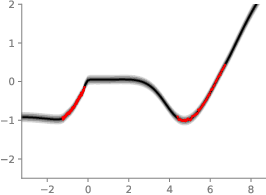
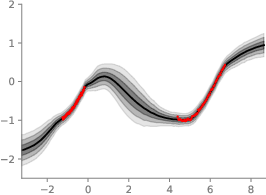
You can try out this example with this Google Colab notebook.
IVON redefines the NN training
I know, I know, this is a bold claim. But this is actually the part I am the most excited about. Allow me to explain.
On top of the mean, the variance from the Gaussian distribution learned by IVON provides a new set of information. Our paper shows that this additional information can be used to achieve many cool things:
- Sensitivity analysis: we can identify the most influential samples, and less important data can also be spotted and potentially pruned.
- Model merging: we can easily merge IVON-trained models that are fine-tuned on different datasets to obtain an improved or edited model without retraining.
- Data-free validation: we can directly estimate leave-one-out cross-validation loss, so early stopping can be done without a separate validation set and all data can be used for training.
- Uncertainty-awareness: the model can produce sensible uncertainty, and produce low confidence for unknown out-of-distribution samples, saying “I don’t know” instead of wrong prediction with high confidence.
We have discussed all these points in detail in our paper.
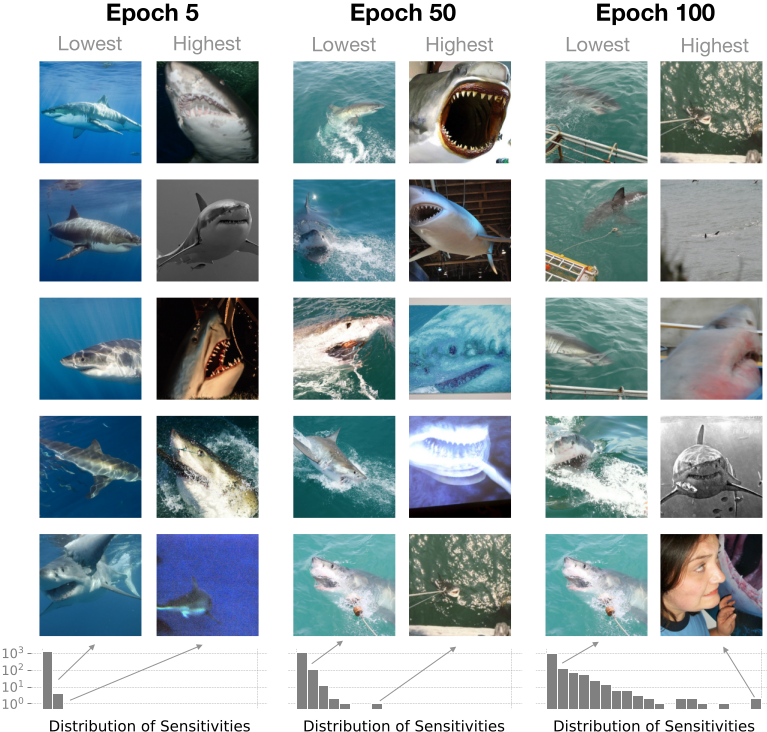
Note that all these are possible at any time of the training process, since the Gaussian distribution is constantly tracked by IVON!
These new possibilities lead me to rethink how neural networks can be trained, and to realize that simple optimizers like SGD and Adam are probably not the end of the story.
How to use IVON in your projects?
Wanna try out the IVON optimizer? We make it easy for you! ![]()
Installation
We provide an official PyTorch implementation of IVON as a PyPI package. You can install it with the command
pip install ivon-opt
Setting up the optimizer
Our ivon-opt package simply contains an IVON class which is a PyTorch optimizer (inherits from torch.optim.Optimizer). We can import and instantiate it as follows:
import ivon
# define your PyTorch model here
model = ...
# define the IVON optimizer like this
optimizer = ivon.IVON(
model.parameters(),
lr=...,
ess=...,
hess_init = ...,
beta1 = ...,
beta2 = ...,
weight_decay = ...,
...
)
Similar to Adam, IVON also has hyperparameters such as learning rate (lr), weight decay, and two momentums (beta1, beta2). Additionally, it asks for the effective sample size (ess) to have a rough idea of how many training samples are out there, as well as an optional hess_init argument to adjust the initial variance of the Gaussian it is tracking.
Some quick tips for setting up the arguments of IVON:
-
lr: should typically be higher than SGD; -
ess: setting to the sample size of the training set is a good start; -
hess_init: typically 0.01 ~ 1 works well. Too small values lead to too noisy weight samples and unstable training, whereas too large ones lead to near deterministic behavior; -
beta1: typical gradient momentum,0.9is a good start; -
beta2: should be rather close to 1 (e.g.0.99999), otherwise instabilities might occur; -
weight_decay: similar to the values used for SGD/Adam.
We have provided a detailed guide in the appendix of our paper for setting up these hyperparameters of IVON, feel free to check it out!
Training with IVON
Training with IVON is largely the same as the usual routine with SGD/Adam, except for an additional weight sampling step. for IVON to do Bayesian learning, it needs to collect sample gradients from weights drawn from the current estimated Gaussian weight distribution.
This can be achieved by wrapping the feed-forward/backward step with a Python context method from IVON, .sampled_params(train=True), which temporarily injects a weight sample into the model. A typical training step with IVON looks like the following:
with optimizer.sampled_params(train=True):
optimizer.zero_grad()
train_output_sample = model(train_input)
loss_sample = lossfn(train_output_sample, target)
loss_sample.backward()
optimizer.step()
Note that the argument train=True is necessary, as it tells IVON to collect the sample gradient when exiting the context.
Additionally, as we have shown in our paper, if you are willing to spend extra computational budget, you can even draw multiple samples to further improve the training. This can be easily achieved with a for loop:
for _ in range(train_mc_samples):
with optimizer.sampled_params(train=True):
optimizer.zero_grad()
train_output_sample = model(train_input)
loss_sample = lossfn(train_output_sample, target)
loss_sample.backward()
optimizer.step()
Running evaluations
There are two ways to do inference with models trained by IVON.
1. Bayesian prediction
This is the inference method that gets the full benefit out of the Bayesian modeling of IVON. In this case, we average the probabilistic predictions from multiple weight samples drawn from the Gaussian distribution learned by IVON.
Our paper shows that increasing sample size leads to improved performance, and typically around 16~64 weight samples are sufficient to obtain good results.
To implement Bayesian prediction, we again use the sample context .sampled_params from the ivon optimizer:
output_samples = []
for _ in range(eval_mc_samples):
with optimizer.sampled_params():
eval_output_sample = model(eval_input)
output_samples.append(eval_output_sample)
You can then average the prediction samples to get the final probabilistic prediction, which for classification tasks can be implemented as follows3:
# log probability of BMA prediction + log(num_classes)
bma_logits = torch.logsumexp(
# stacked sample log probabilities
torch.log_softmax(
torch.stack(output_samples, axis=0),
axis=-1,
),
axis=0,
)
2. Fast estimate at the mean
If you need fast inference speed. You can also directly use the mean of the Gaussian weight distribution. This approach performs the so-called MAP estimation. In this case, as the mean is stored in your model, you can do the inference the usual way without drawing any weight sample:
eval_output = model(eval_input)
This point estimate at the mean also produces good test-time predictions. However, it tends to have sub-optimal uncertainty estimation similar to SGD/Adam.
Examples using IVON
Wanna quickly try out IVON? On top of the two Google Colab notebooks on the 2D loss landscape and 1D regression examples, we have also provided another Colab notebook on MNIST image classification. This MNIST example should give you a concrete idea of how IVON is used in typical deep-learning setups.
Also, we will release the source code that reproduces the experiments in our paper, stay tuned!
How about JAX …
Great choice ![]() I got your back! I have also implemented IVON with JAX, checkout this github repository.
I got your back! I have also implemented IVON with JAX, checkout this github repository.
Conclusion
I hope that this post has piqued your interest in our IVON optimizer. Please feel free to try it in your projects and let us know what you think!
- ArXiv: arxiv.org/abs/2402.17641
- Github (IVON PyTorch package): github.com/team-approx-bayes/ivon
- Github (experiments): github.com/team-approx-bayes/ivon-experiments
- Github (IVON JAX implementation): github.com/ysngshn/ivon-optax
-
bibtex
@inproceedings{shen2024variational, title={Variational Learning is Effective for Large Deep Networks}, author={Yuesong Shen and Nico Daheim and Bai Cong and Peter Nickl and Gian Maria Marconi and Clement Bazan and Rio Yokota and Iryna Gurevych and Daniel Cremers and Mohammad Emtiyaz Khan and Thomas Möllenhoff}, booktitle={International Conference on Machine Learning (ICML)}, year={2024}, }
Until next time ![]()
-
This overhead can be reduced further, since the current implementation is not fully optimized for best performance. We are working on it now. ↩
-
An improved variant of Adam that we use for Adam baselines. ↩
-
Computations are done in log domain for better numerical precision. ↩